
PCIe Gen 4 Expansion chassis- a future oriented choice
When we are looking for GPU expansion solutions, most likely we are lacking the computing power to meet our requirement. To make our budgets effective, we must at least have a clear idea on the number of GPUs that we need, the number of hosts we have, the operation and maintenance budget, and product life of the solution.
Large companies may care more about performance while being less sensitive to costs, and they are upgrading their infrastructures to the newest technology available no matter what. However, in small-medium scale enterprises, we want a solution that would last longer while providing acceptable performance. In this case, a GPU expansion box that supports PCIe gen 4 would be a better choice. Since PCIe is a backward compatible technology, PCIe gen 3 devices could run smoothly as usual in a Gen4 chassis. In addition, when we are going for more powerful upgrades (i.e. adapting a Gen 4 GPUs, SSDs), a Gen 4 solution leaves us more room to do so.
Thanks to the advanced manufacture design, PCIe gen 4 GPUs are more energy-efficient than the gen 3, the performance per watt of gen 4 devices is going to be higher than that of gen 3, making PCIe Gen 4 system a worthy investment for most enterprises or individuals.
Aspects that you should pay special attention to when choosing your expansion chassis
The PCIe Gen 4 standard was announced in 2017, the Gen 4 GPUs such as AMD Radeon Instinct and nVidia A100 were introduced to the market in recent years. Many enterprises would love to take the advantages of these more powerful GPUs by incorporating them to existing infrastructures. Among different GPU solutions available on the market, it may be challenging to determine which one best fits your needs. However, there are several things that you must take into consideration when making purchase decisions for expansion chassis, especially when you are going to use high performance GPUs like nVidia Tesla.
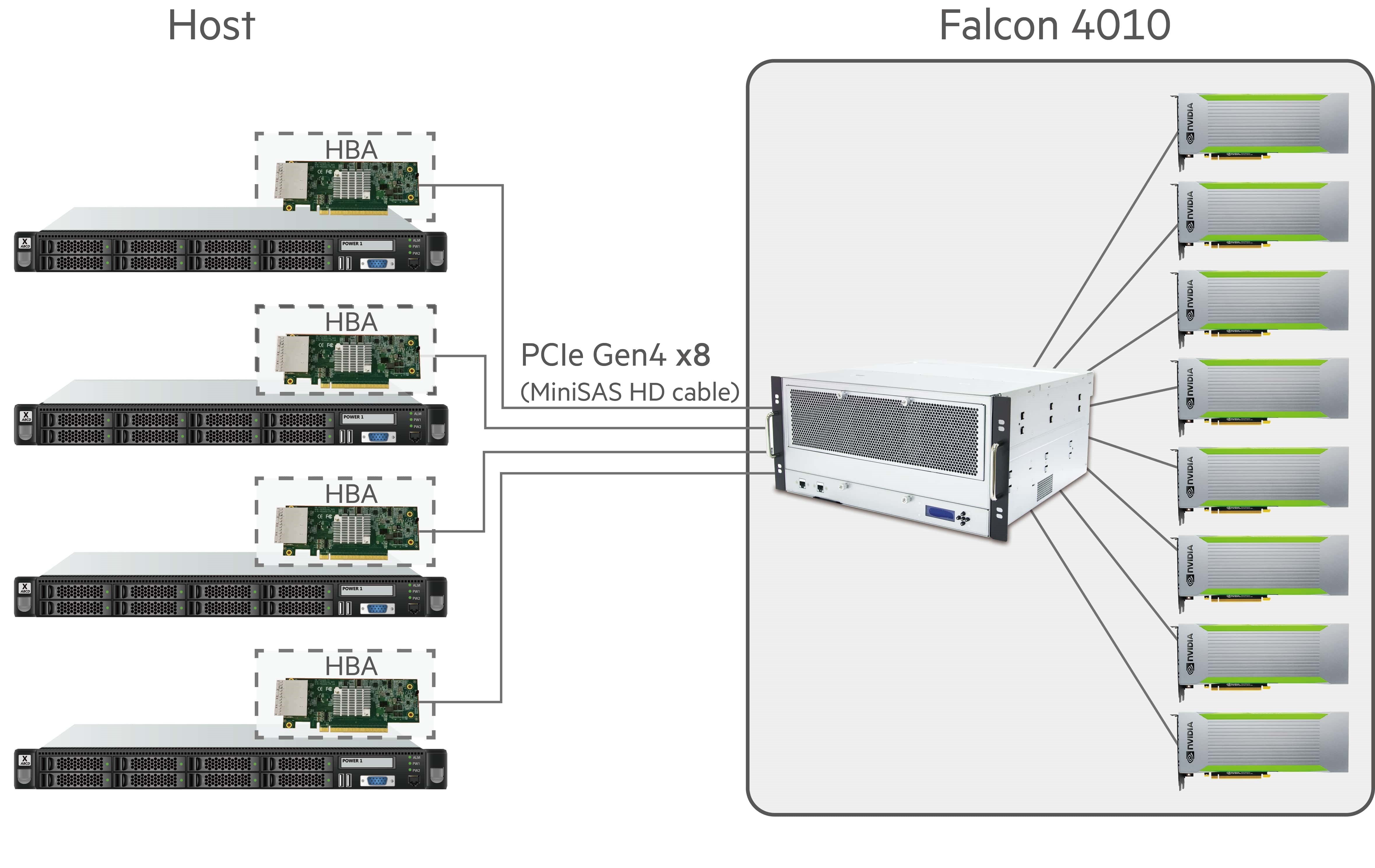
1. Number of host servers you have- PCIe switch matters
There are two PCIe switch modes available, the fan-out mode and the fabric mode. The PCIe fan-out mode allows device pool expansion, but it is limited to single host settings as there is only one upstream port from the switch. If you are running two or more hosts, PCIe fabric is your better choice because there are two upstream ports available, enable sharing of computing resources (GPUs/ NVMe SSDs/ FPGAs) in one chassis to more than one host. You can learn more about the differences between PCIe fan-out mode and PCIe fabric mode in the comping up H3 platform blog.
8 GPUs are shared among the connected 4 hosts.
2. Power supply that can boot up the entire chassis
Let us talk about power supply in detail using nVidia RTX 2080-TI GPU as example. The power consumption of 2080-TI is 260W but nVidia official suggests 650W power supply and 8pin+8pin for the power connector.

nVidia RTX 2080-TI thermal power specs. Retrieved from https://www.nvidia.com/en-us/geforce/graphics-cards/rtx-2080-ti/
We suppose it is because GPUs consume 1.8~2 times of power when boot from sleep mode. If you have four of these GPUs installed, despite other devices, you will need at least 2,600W just for the GPUs. You might be using GPUs of other makes but pay attention to the power supply your GPU requires, and make sure you have enough power for the entire expansion box to avoid unexpected shutdowns.
3. Energy saving- control the power of each PCIe devices and empty slots
The GPUs are very power consuming, and we would waste a lot of electricity when devices are idle. However, it is impractical to unplug the server just to save energy for one idled GPU as the CPU and other devices in the server are still working, and it would take too much effort to detach the GPU from the server, thus leaving energy waste an unsolvable issue. Even though your devices are treated as direct attachments to the host, the expansion chassis is external to the host server. Unplugging the expansion chassis simply means that your host loses a couple GPUs to speed up its computing process, and the host itself remains working. Base on the nature of expansion chassis, H3 Platform has brought it further to achieve power control for individual device. Users can turn-on and off each slot according to the usage. Furthermore, users can set the empty PCIe slots or devices not in used to standby status with H3 Platform solutions. The standby devices will be given 12V power, and when the slot is turned off, there will still be 3.3V power for the system to keep track on the device. This way, users can manage the power consumption of devices easily while being able to react quickly when the device becomes idled or when it fails.
4. Cooling system- airflow (CF/M), redundant fan design, and hot swappable
GPUs generate a lot of heat when operating, and GPU performance can drop significantly when the temperature is too high. Cooling might not be the biggest problem for gaming/entry-level rendering GPUs where fans and heat sinks are attached. However, not many high-end GPUs (i.e. RTX, Tesla) are having direct attached fans. With only heat sink, the heat is discharged passively, and the devices can go overheat easily.
For a typical high-end GPU, we need around 12~20 cubic feet per minute airflow to keep the temperature down at 25~30 °C, and system fans are usually used to meet that airflow requirement. Nonetheless, we should always have a redundant fan deign just in case one fan goes out of order. In addition, it would be even better to have a hot swapping design, so the system gets to run normally while we are making a replacement.
5. Easy device management-reduce server downtime
Device replacement is a time-consuming process. The server must be shut down before detaching any device, otherwise you would experience a system crash and maybe burn your motherboard. Also, it is dangerous to plug the devices out while the server is running, the electric shock can be fatal. An expansion chassis can easily solve this problem as the power supply is separated from the host. Shutting down the power of expansion chassis will not affect your host, and you would not have to worry about electric shocks when removing/adding devices as the chassis is power off. Keep in mind that you should stop all activities from the chassis before turning it off.
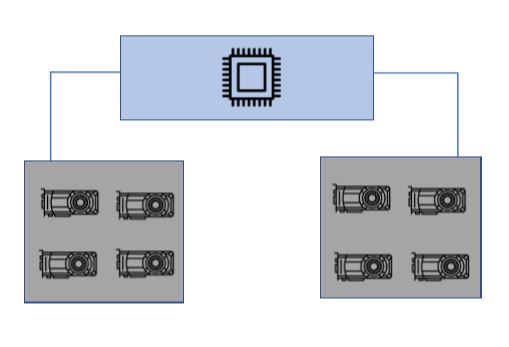
Shutting down servers can be a costly action for some businesses. Your services would be off-line, and no profit is generated during the period. The more time you spend on replacing devices, the greater lose you would suffer. However, you can set up two expansion chassis. Your server could run with half resources while you shut one chassis down for maintenance.
2 chassis 1 host setup
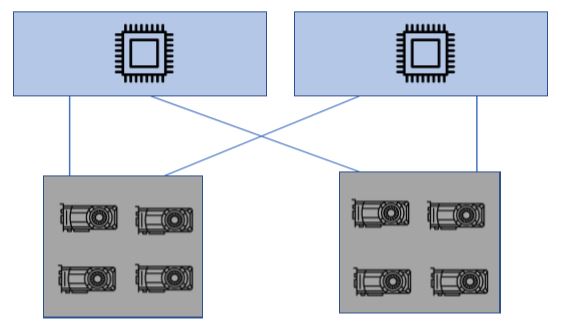
Or you can check out the expansion solutions from H3 platform with a unique drawer design. With separated drawers, users would not need an extra expansion chassis for backup plan, simply turn off the drawer which the problematic device is in while the other drawers remain running.
2 chassis to 2 hosts setup
Monitor the health status of every device you have
Device failures or decline in performance are something that we never want to see. Moreover, if we are not aware of device failures in time, the result coming after it can be very unpleasant. It is important to monitor the health status such as temperature, GPU utilization rates, data transfer speeds and power consumptions of your chassis and devices, so that you could react properly to any issue (i.e. IO bottleneck, device P2P disability, low GPU utilizations…) happened to your systems. In the blog How to Figure Out the IO Bottleneck by Using Performance Analytics, we have discussed how device status information benefits in terms of performance optimization. There are several ways to collect these device data, you could write a program to read the performance data of your devices. If you are using nVidia GPUs, you can execute the NVQUAL command, it helps you to test your signal integrity, CUDA P2P, cooling…etc. Also, there are various benchmark testing software you could find online that can help you to check out your device performance, though applying the software to every device you have may take some effort. Or you can use the H3 management center to monitor all your device performances. The sensors are built in H3 Platform chassis to read all this information, making the data available anytime (visit http://h3platform.com for detail). No matter which approach you take, you should always monitor your devices, because it helps you to identify any system issue faster, preventing tragic from happening before it is too late.